AMD Targets Faster Local LLMs: Ryzen AI 300 Hybrid NPU+iGPU Approach Aims to Accelerate Prompt Processing
The landscape of local Large Language Model (LLM) inference is rapidly evolving, driven by a technically savvy enthusiast community constantly seeking the best performance-per-dollar from their hardware. While high-VRAM discrete GPUs, often in multi-card configurations, have dominated the scene for tackling larger models, the quest for efficient inference on more accessible hardware like laptops and mini-PCs continues.
AMD is now throwing its hat more firmly into this ring, not just with silicon, but with a dedicated software strategy aimed at leveraging the heterogeneous compute units within their upcoming Ryzen AI 300 processors.
Enter “Lemonade Server,” an AMD-backed, open-source project built upon the ONNX Runtime-GenAI framework. This initiative signals AMD’s intent to make the Neural Processing Unit (NPU) – a component often sidelined in current LLM inference workflows – a relevant player, particularly for accelerating the critical prompt processing phase.
For the hardware enthusiast meticulously balancing VRAM capacity, memory bandwidth, and budget, this development warrants close attention. NPUs have, until now, largely been a footnote in the LLM discussion, overshadowed by the raw parallel processing power and memory bandwidth of GPUs.
AMD’s strategy with Ryzen AI 300 and Lemonade Server attempts to change that narrative by employing a hybrid NPU + integrated GPU (iGPU) execution flow.
The Hybrid Architecture: NPU for Prefill, iGPU for Generation
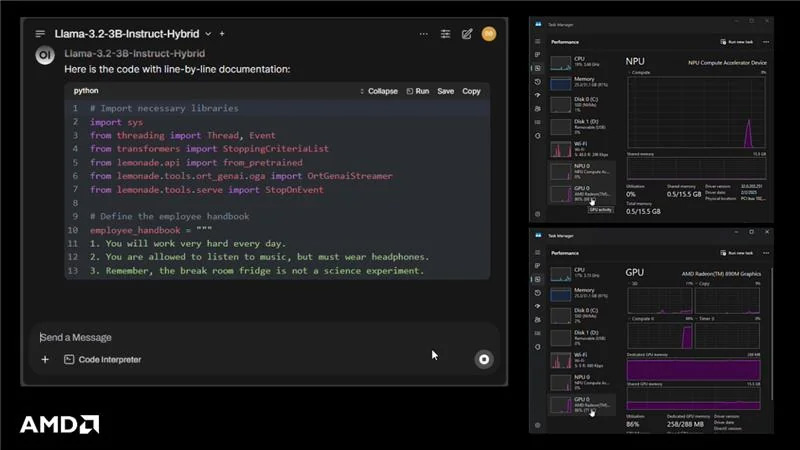
AMD’s Ryzen™ AI architecture, featured in the upcoming 300-series mobile processors (“Strix Point” and the presumably higher-end “Strix Halo”), integrates three distinct compute engines: traditional Ryzen CPU cores, Radeon™ Graphics (iGPU), and the XDNA-based NPU. The core idea behind AMD’s new software approach is to intelligently distribute the LLM workload across these units for optimal efficiency and performance, specifically targeting smaller, quantized models suitable for edge devices.
The workflow, facilitated by Lemonade Server and the underlying ONNX Runtime-GenAI engine, operates as follows:
Prompt Processing (Prefill)
When a user submits a prompt (which can often involve processing a significant context window), this compute-intensive phase is primarily offloaded to the NPU. AMD suggests the NPU offers superior compute throughput for this task compared to the iGPU. The goal here is minimizing the Time To First Token (TTFT) – the latency users experience before the model starts generating its response.
Token Generation (Decoding)
Once the initial prompt is processed, the task of generating subsequent tokens is handed off to the integrated Radeon graphics (iGPU). This phase is often more sensitive to memory bandwidth, an area where iGPUs, accessing the main system DRAM pool (ideally fast LPDDR5X), can offer respectable performance, especially relative to the NPU’s own capabilities.
AMD highlights several potential benefits of this hybrid approach:
- Efficiency: Distributing the load aims to optimize power consumption, crucial for battery-powered devices or small form factor builds where thermal headroom is limited. Assigning tasks to the most suitable compute unit prevents overloading a single component.
- Scalability: While currently focused on the NPU+iGPU combo, the framework is designed with heterogeneous systems in mind, potentially allowing flexibility as hardware configurations evolve.
- Performance: By leveraging the NPU’s compute strength for prefill and the iGPU’s bandwidth access for generation, AMD aims for a balance delivering lower TTFT and respectable Tokens Per Second (TPS) for the target model sizes.
Introducing Lemonade Server: An ONNX-Based Local LLM Server
Spearheaded by AMD developers but hosted under the open-source ONNX (Open Neural Network Exchange) umbrella, Lemonade Server acts as an OpenAI-compatible endpoint for local LLM inference. It is primarily designed for the upcoming Ryzen AI 300-series laptops, codenamed “Strix Point”.
For full NPU and iGPU acceleration capabilities, Windows 11 is currently required, although a CPU-only fallback mode ensures broader compatibility across both Windows and Linux, albeit without the specific hardware acceleration benefits.
The underlying software stack leverages Microsoft’s open-source onnxruntime-genai engine, necessitating models formatted for ONNX. These typically need to be quantized, often to INT4 for weights with bfloat16 activations, using tools like AMD’s Quark quantizer. The project itself is available under an Apache 2 license on GitHub, with installers provided via the project’s releases page.
The project aims to bring some of the usability features familiar from the llama.cpp ecosystem (like a local server interface, benchmarking tools, and Python API) to the ONNX world, specifically tailored for AMD’s new hardware capabilities.
Performance Snapshot: DeepSeek-R1-Distill-Llama-8B (INT4)
AMD provided preliminary benchmark figures run on a pre-release AMD Ryzen AI 9 HX 370 laptop (“Strix Point”) equipped with Radeon 890M graphics and 32GB of LPDDR5X-7500 memory. Focusing on the DeepSeek-R1-Distill-Llama-8B model (quantized to INT4 weights, bfloat16 activations), the results using the hybrid NPU+iGPU flow are as follows:
| Sequence Length | Time To First Token (TTFT) [s] | Tokens Per Second (TPS) [tok/s] |
| 2048 | 5.01 | 17.6 |
| 1024 | 2.68 | 19.2 |
| 512 | 1.65 | 20.0 |
| 256 | 1.14 | 20.5 |
| 128 | 0.94 | 20.7 |
Analysis
The key takeaway here is the TTFT. For enthusiasts running interactive chat sessions or RAG applications, minimizing the initial delay after submitting a prompt is crucial for a good user experience. Processing a 2048-token context in ~5 seconds on integrated hardware is noteworthy, suggesting the NPU is indeed contributing significantly during the prefill stage (~400 tokens/sec prefill rate). The generation speed (TPS) hovering around 17-20 tok/s for an 8B parameter model on integrated graphics is respectable, making it usable for many interactive tasks, though understandably not competing with high-end discrete GPUs.
It’s important to note a current software limitation mentioned by AMD developers: context lengths are presently capped between 2k and 3k tokens depending on the model, preventing tests with much larger contexts that are increasingly common.
Initial Thoughts & Upgrade Path Implications
AMD’s push with Lemonade Server and the hybrid NPU+iGPU approach on Ryzen AI 300 represents a tangible step towards making NPUs relevant for LLM inference on power-constrained devices. The focus on accelerating prompt processing (TTFT) via the NPU is strategically sound, addressing a key latency bottleneck. The provided 8B model benchmarks suggest promising initial results for integrated solutions.
For the price-conscious enthusiast:
- Potential: Ryzen AI 300-based laptops or mini-PCs could become compelling, power-efficient platforms for running smaller (sub-10B parameter) quantized models locally, especially if TTFT is a priority.
- Upgrade Path: Such a system might serve as an excellent entry point or a complementary device to a larger desktop rig. It could handle smaller model tasks efficiently, freeing up VRAM-heavy discrete GPUs for larger model inference.
- Caveats: The ecosystem is nascent. Reliance on ONNX, the current Windows limitation for acceleration, and the context size cap are significant hurdles compared to the mature llama.cpp ecosystem.
The success of this initiative hinges heavily on software maturation, particularly expanding context length limits, and addressing the community’s strong preference for llama.cpp integration and robust Linux support. If AMD can navigate these software challenges and the hardware delivers on its promise, the Ryzen AI 300 series could carve out a significant niche in the affordable local LLM inference market, offering a potent blend of CPU, iGPU, and, finally, meaningful NPU performance. We will be watching closely as hardware becomes available for independent testing and the software stack evolves.




Leave a Reply
No comments yet.