Nvidia’s G-Assist is Using Llama 3.1 with Llama.cpp – Here’s the Proof!

As enthusiasts of local LLM inference and hardware performance, the moment we saw Nvidia’s Project G-Assist, one question immediately came to mind: how does it run under the hood? While Nvidia’s official materials emphasize its gaming-focused features, we dug deeper into its actual implementation. Surprisingly, G-Assist is powered by Llama 3.1 8B and runs locally using the open-source inference engine Llama.cpp – making it a familiar tool for those of us running quantized models on our own hardware.
What is Nvidia G-Assist?
Nvidia recently unveiled Project G-Assist as an AI-powered assistant for GeForce RTX users, integrated within the Nvidia App. Its core functions include:
- Optimizing game settings dynamically based on hardware.
- Overclocking GPUs in real-time for better performance.
- Monitoring system bottlenecks with live performance graphs.
- Managing game launches and recordings via voice and text commands.
Despite the marketing as a gaming assistant, G-Assist is essentially a chatbot enhanced with retrieval-augmented generation (RAG) and system tools. This makes it a lot more than just a glorified FAQ bot.
What LLM Powers Nvidia G-Assist?
Nvidia states that “Project G-Assist uses a specially tuned Small Language Model (SLM).” However, after inspecting its system files, we found that it’s actually running Llama 3.1 8B Instruct with 4-bit GGUF quantization. If you’ve ever set up a local LLM, you can probably guess the inference framework – Llama.cpp.
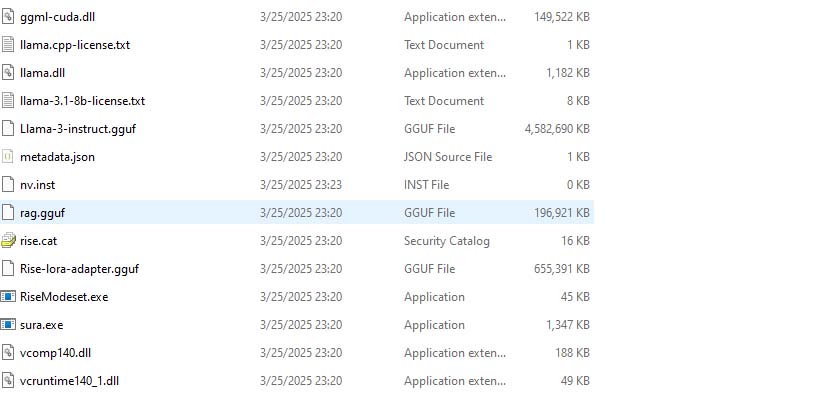
Llama.cpp is an open-source C++ inference engine optimized for running Llama models on consumer hardware, particularly with quantized formats that significantly reduce VRAM requirements. It’s lightweight, efficient, and allows for rapid inference even on mid-range GPUs. Nvidia’s choice of Llama.cpp is particularly interesting given their own Chat with RTX framework, which they opted not to use for G-Assist, likely due to its higher resource requirements.
To evaluate G-Assist’s resource usage, we tested it on a system with an RTX 3090 (24GB VRAM) and 32GB of system RAM.
The Takeaway
G-Assist’s implementation is a fascinating case study in local AI inference. Nvidia’s use of Llama 3.1 8B and Llama.cpp underscores the viability of open-source models for real-time applications. However, its VRAM requirements mean that only high-end GPUs can comfortably run both G-Assist and demanding games simultaneously. If you’re already running local LLMs, this offers a glimpse into how a lightweight model can be integrated into a consumer-facing application.
Would you use G-Assist, or do you prefer running models on your own terms? Let us know your thoughts.