How Much VRAM Does Nvidia G-Assist Use While Gaming?
As enthusiasts of local LLM inference and hardware performance, the moment we saw Nvidia’s Project G-Assist, one question immediately came to mind: how much VRAM does it consume while answering your questions? Today, we’re diving deep into G-Assist’s technical implementation, its model, and, most importantly, its impact on VRAM usage during gaming sessions.
What is Nvidia G-Assist?
Nvidia recently unveiled Project G-Assist for GeForce RTX users, introducing an AI-powered assistant designed to help optimize gaming performance. Currently in an experimental phase within the Nvidia App, G-Assist can:
- Optimize game settings based on user preferences and hardware capabilities.
- Overclock GPUs dynamically to improve performance.
- Monitor and analyze system bottlenecks with real-time performance graphs.
- Launch games and manage recordings through voice and text commands.
While Nvidia frames G-Assist as a gaming assistant, under the hood, it’s essentially a chatbot with retrieval-augmented generation (RAG) and additional tools for system optimization. This makes it far more than just a simple FAQ bot.
Nvidia states that “Project G-Assist uses a specially tuned Small Language Model (SLM).” However, after analyzing the system files, we found that it is, in fact, running Llama 3.1 8B Instruct, likely a fine-tuned version, using 4-bit GGUF quantization.
How Much VRAM Does Nvidia G-Assist Use?
To answer this question, we tested G-Assist on a Windows 11 system with an RTX 3090 (24GB VRAM) and 32GB of system memory.
Here’s what we found:
- Idle VRAM Usage: When G-Assist is simply running in the background, waiting for input, it consumes 1.2GB of VRAM.
- Inference VRAM Usage: When actively answering a question, VRAM usage spikes to 6.1GB, with an additional 5GB of system memory usage.
To further stress-test G-Assist, we prompted it with a 1,000-token query. The response time was around 9 seconds for the first token. As a comparison, we loaded the same model into LM Studio, which took just 0.25 seconds for the first token. However, this is because LM Studio pre-loads the model into VRAM, whereas G-Assist dynamically loads the model only when needed, freeing up resources for gaming.
VRAM Usage While Gaming
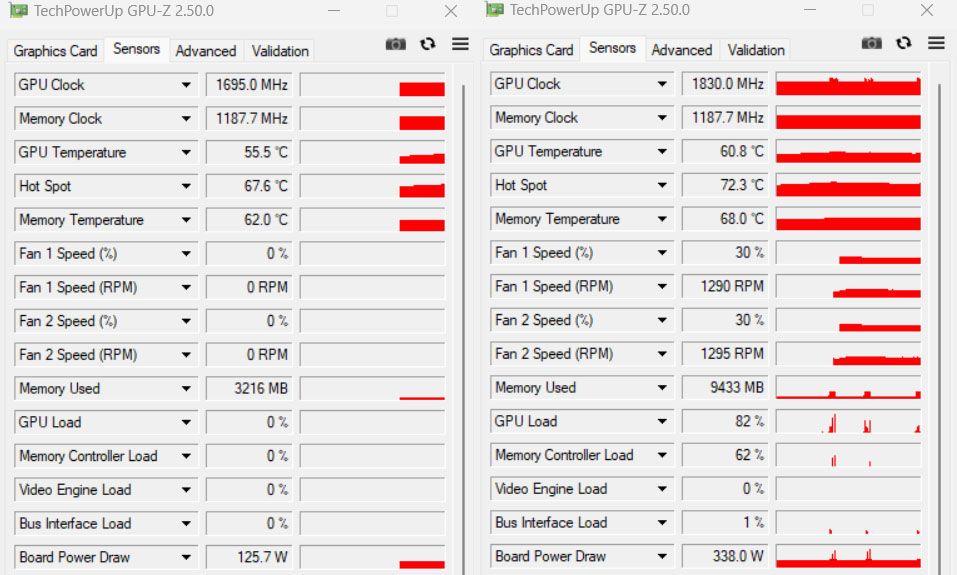
To test G-Assist’s real-world impact on gaming, we ran Path of Exile 2, a relatively modest game that consumes around 4GB of VRAM at 1440p with DLSS 4 Quality. Here’s the system load before and after enabling G-Assist:
- Before G-Assist: Total VRAM usage was 8.8GB.
- During G-Assist Inference: With G-Assist answering a question, VRAM usage spiked to 15GB (game + G-Assist’s 6.1GB + system load).
This significant VRAM consumption is one of the key reasons Nvidia has set a 12GB VRAM minimum requirement for G-Assist and does not allow installation on lower-VRAM GPUs. There are rumors that Nvidia may introduce support for GPUs with less VRAM, but this would require either switching to a smaller model or offloading inference to system memory, which could impact performance.
Conclusion
Nvidia G-Assist is a powerful tool, leveraging an optimized Llama 3.1 8B model with 4-bit quantization to provide real-time gaming assistance. However, its VRAM footprint is not insignificant:
- Idle mode: 1.2GB VRAM
- Active inference: 6.1GB VRAM + 5GB system RAM
- Gaming + G-Assist: Expect an additional 6.1GB VRAM overhead
For high-end GPUs with 24GB or more VRAM, this impact may be manageable, but for 12GB VRAM users, running demanding games alongside G-Assist could push memory limits. Nvidia’s decision to enforce a 12GB minimum makes sense, but it remains to be seen whether a lower-VRAM alternative will be offered.
For now, if you’re an enthusiast balancing local LLM inference and gaming, be aware of G-Assist’s VRAM usage before enabling it. Let us know in the comments—would you use G-Assist, or do you prefer running models locally with full control?



