See What GPU to Use with FLUX.1 AI Image Model
As AI enthusiasts and developers, we’ve been exploring the new FLUX.1 model, a powerful diffusion image generation model that has taken the community by storm. A question we frequently encounter is, “What GPU do I need to run FLUX.1?” After testing across different setups, we’re ready to share what we found. This guide breaks down the GPU requirements for different versions of FLUX.1, focusing on GPUs that can load the entire model into VRAM.
Understanding VRAM Requirements for FLUX.1 Versions
When selecting a GPU for FLUX.1, VRAM (Video RAM) is the key factor to consider. Both Dev and Schnell FLUX.1 models comes in several quantization versions, each with different VRAM needs depending on whether you’re using the full-size model or a quantized version. And because FLUX.1 is a transformer-based diffusion model, it can now be quantized to the GGUF file format, allowing for lower quantization levels (i.e., reduced VRAM requirements) while maintaining high image generation quality.
Here’s a quick overview:
- Official FP16 Models: The most accurate model. Require about 24 GB of VRAM.
- Q8, FP8 and NF4 Quantized Versions : These versions reduce the VRAM requirement to around 13 GB. The Q8 GGUF model is the best option – comes quite close to the FP16 version.
- Lower Quantized Versions: Depending on the level of quantization (Q2, Q3, Q4, Q5 and Q6), these models need between 6 GB and 16 GB of VRAM.
- While some frontends allow you to offload parts of the model to system RAM, for optimal performance, we recommend using GPUs that can contain the entire FLUX.1 model in VRAM.
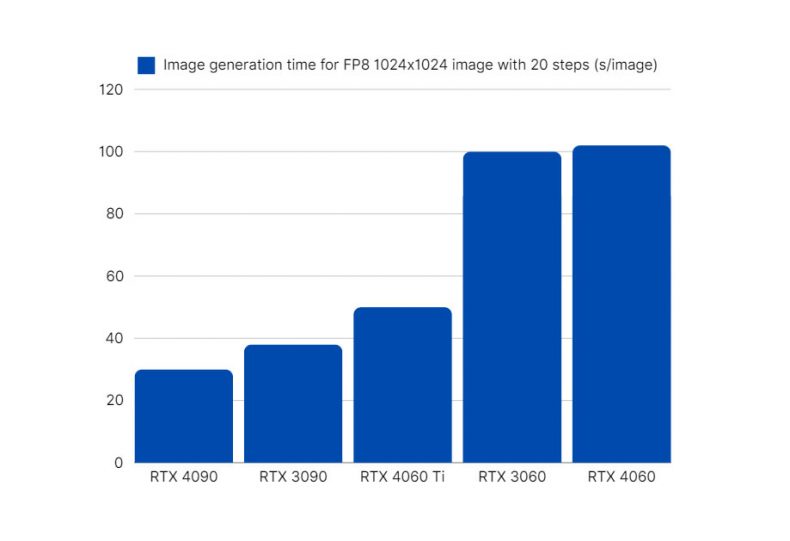
To help you gauge where your system stands and understand the impact of different hardware, we’ve compiled a table summarizing our benchmarks dedicated to FLUX.1 performance on different GPUs.
| GPU | VRAM (GB) | RAM (GB) | FP16 (seconds) | FP8 (seconds) | NF4 (seconds) |
|---|---|---|---|---|---|
| RTX 5090 | 32 | 96 | 9 | 6 | – |
| RTX 4090 | 24 | 64 | 18 | 14 | – |
| RTX 3090 | 24 | 64 | 40 | 30 | – |
| RTX 4070 Ti | 12 | 32 | 49 | 49 | 28.4 |
| RTX 3070 Ti | 8 | 64 | 77 | 77 | – |
| RTX 3060 | 12 | 32 | 632.75 | 400 | 138 |
| RTX 4060 Ti | 16 | 128 | 92.5 | 49 | 47 |
| RTX 2060 | 6 | 40 | – | – | 156 |
| RX 6950 XT | 16 | 36 | – | 400-800 | – |
24 GB+ VRAM: Official FP16 Models
For those seeking the highest quality with FLUX.1, use Dev and Schnell at FP16. These models require GPUs with at least 24 GB of VRAM to run efficiently.
Recommended GPUs:
- NVIDIA RTX 5090: Currently the best GPU for FLUX.1
- NVIDIA RTX 4090: This 24 GB GPU delivers outstanding performance.
- NVIDIA RTX 3090 / 3090 Ti: Both provide 24 GB of VRAM, making them suitable for running the full-size FLUX.1 models without a hitch.
In our tests, the RTX 5090 stood out with great speed and efficiency, though the RTX 3090 or 4090 remains a the best option, especially if you can find it at good price as second hand.
16GB VRAM: Q8, FP8 and NF4 Quantized Versions
For users who need to balance performance with hardware accessibility, Q8 (GGUF), FP8 and NF4 quantized versions of FLUX.1 are excellent choices. These versions significantly reduce the VRAM requirement between to 16 GB.
Recommended GPUs:
- NVIDIA RTX 4070 Ti Super: A well-rounded choice with 16 GB of VRAM, providing excellent performance with Q8 quantized FLUX.1 versions.
- NVIDIA RTX 4060 Ti :Best price to performance ratio it this category. Great card for both gaming and AI.
- AMD Radeon RX 6800: This GPU comes with 16 GB of VRAM, offering plenty of headroom for running the models models.
In our experience, the RTX 4060 Ti provided an optimal blend of price, power efficiency and performance, making it a standout option for those working with this level of quantization.
12GB VRAM: Q6 and Q5 Quantization
For those seeking an optimal balance between price and performance, GPUs with 12 GB of VRAM are an excellent choice for running FLUX.1. The Q6 and Q5 quantized versions offer image quality that is remarkably close to the original, while reducing VRAM requirements to a more accessible range of 12 GB. This makes them an ideal solution for users who want high-quality output without the need for high-end hardware.
Recommended GPUs:
- NVIDIA RTX 4070: The fastest performer in this segment, offering exceptional speed and efficiency for running Q6 and Q5 quantizations.
- NVIDIA RTX 3060: With 12 GB of VRAM, this GPU comfortably handles most Q6 and Q5 quantized versions, making it a highly affordable and effective option for AI projects.
In our experience, the RTX 4070 delivers an outstanding blend of price, power efficiency, and performance, making it a standout choice for users working with these quantized versions of FLUX.1.
8 GB VRAM: GGUF Quantized Versions
For those with more budget-conscious setups or older hardware, the lower GGUF quantized versions of FLUX.1 (Q2, Q3, Q4) offer a path forward. These versions are designed to fit into GPUs with as little as 6 GB, depending on the specific quantization.
Recommended GPUs:
- NVIDIA RTX 4060: The fastest performer
- NVIDIA RTX 3050: Another cheap 8 GB option, suitable for lower FLUX.1 quantization.
- AMD Radeon RX 6600 XT: This 8 GB GPU offers good performance for running the smaller GGUF quantized models.
In our testing, the RTX 4060 proved to be a pleasant surprise, handling the GGUF versions with efficiency, making it a great choice for those just starting with FLUX.1
GPU power consumption during FLUX.1 image generation
These are couple GPU tested for power draw during on FLUX.1 image generation.
| Model | Memory | Tensor Cores | TDP |
|---|---|---|---|
| GeForce RTX 3060 | 12 GB GDDR6 – 192 bit | 112 | 171.8W |
| GeForce RTX 3090 | 24 GB GDDR6X – 384 bit | 328 | 361.1W |
| GeForce RTX 4070 Ti | 16 GB GDDR6X – 256 bit | 264 | 292.2W |
| GeForce RTX 4060 Ti | 8/16 GB GDDR6 – 128 bit | 136 | 160.2W |
| GeForce RTX 4090 | 24 GB GDDR6X – 384 bit | 512 | 473.2W |
| GeForce RTX 4090 | 32 GB GDDR7 – 512 bit | 680 | 525.1W |
NVIDIA vs. AMD: A Performance Comparison
While both NVIDIA and AMD GPUs can run FLUX.1, NVIDIA generally leads in AI performance due to better support for CUDA and optimized drivers. In our tests, NVIDIA cards consistently outpaced their AMD counterparts, especially in terms of inference speed and stability.
That said, AMD GPUs remain a viable option, particularly if you already own one or are looking to save on costs. The GGUF quantized versions of FLUX.1 run well on AMD hardware, though you might experience longer generation times compared to NVIDIA GPUs.
Conclusion
The best GPU for FLUX.1 largely depends on the specific model version you plan to use and your available budget. For those who prioritize quality and have the budget, a high-end NVIDIA GPU with at least 24 GB of VRAM is the optimal choice. However, if you’re working with quantized models, GPUs with 12 GB or even 8 GB of VRAM can still deliver excellent results.
What’s YOUR experience running FLUX.1? Share your GPU setup and findings in the comments!

Allan Witt
Allan Witt is Co-founder and editor in chief of Hardware-corner.net. Computers and the web have fascinated me since I was a child. In 2011 started training as an IT specialist in a medium-sized company and started a blog at the same time. I really enjoy blogging about tech. After successfully completing my training, I worked as a system administrator in the same company for two years. As a part-time job I started tinkering with pre-build PCs and building custom gaming rigs at local hardware shop. The desire to build PCs full-time grew stronger, and now this is my full time job.11 Comments
Submit a Comment
Related
Desktops
Best GPUs for 600W and 650W PSU
A high-quality 500W PSU is typically sufficient to power GPUs like the Nvidia GeForce RTX 370 Ti or RTX 4070.
Guides
Dell Outlet and Dell Refurbished Guide
For cheap refurbished desktops, laptops, and workstations made by Dell, you have the option…
Guides
Dell OptiPlex 3020 vs 7020 vs 9020
Differences between the Dell OptiPlex 3020, 7020 and 9020 desktops.
New to AI image generation here. What’s the difference between FP16 and quantized models? Is the quality difference noticeable?
FP16 refers to “floating point 16-bit,” essentially the full-precision model. Quantized models use lower precision (like 8-bit) to reduce VRAM requirements. This can slightly impact image quality, but the differences are often subtle, especially for FLUX.1 with higher quantization levels like Q8.
This is a great overview of GPUs for FLUX.1, but I’m curious about power consumption. Some of us are on a budget and need to consider electricity costs. Could you add information on the power draw of these GPUs?
You raise a valid point! Power consumption is definitely something to consider. I’ve added a section with estimated wattage for couple of GPU during FLUX.1 inference. Keep in mind that actual power draw can vary depending on several factors like overclocking, cooling and other hardware inside your PC.
I’m currently trying to run the Dev/Schnell model using the Python library `diffusers` on my RTX 3090, but I’m running into some issues with VRAM usage.
Right now, I can only manage to run the model by using `pipe.enable_sequential_cpu_offload()`, but this approach doesn’t load the full model into VRAM and ends up using only a small portion of the available VRAM.
Has anyone successfully run the whole model directly in VRAM on a 3090? If so, could you share what approach or optimization techniques you used to make it work?
Try loading the FP8 or Q8 GGUF quantized version, they are 12 GB. They have lower VRAM requirements with similar quality to the full precision model.
Any particular reason that you left out the 7900XTX? It has 24 gigs of vram and outperforms the 3090 and 4080 Super all while being less expensive.
I don’t have a 7900 XTX to test at the moment. 🙂
However, from the benchmarks I’ve seen online, the 7900 XTX is slower than the RTX 4080 16GB with Automatic1111 and Stable Diffusion.
At the moment, if I were to buy a GPU specifically for AI tasks (like LLMs and diffusion models), I’d definitely go for a secondhand RTX 3090. It’s around $700, has CUDA, 24 GB VRAM, and is much easier to set up for these types of applications.
Is the VRAM cooling of the 3090 not a known issue? Half of the modules is located under the backplate. I’ve come across countless threads/subreddits where it caused serious problems with certain workloads.
I’m still torn between the 3090 Ti (+undervolt) and RTX 4080S. I also like to game (DLSS/FrameGen etc.). Unfortunately my budget isn’t ready for a 4090 which has the best of both worlds.
In my home setup, I’m running an RTX 3090 with undervolting inside a Fractal Design Meshify C, which is a pretty compact case. For cooling, I have two 120mm intake fans at the front, one 120mm intake fan on top, and a 120mm exhaust fan at the back. The cooling is not an issue.
VRAM is king with Nvidia, get the RTX 3090, avoid anything smaller than 24GB. the RTX 4090 or 5090 is simply too overpriced at this time.
Use Swarmui with Comfyui as the backend access the Comfy workflow on Swarmui then Comfy Manger, the Custom addons search for Flux performance or speed for optimizing the performance speed or rendering speed.
A Night & day difference. Takes about 40-45 seconds to render a 1414×1414 size image using Flux 1 Dev FP16 model