RTX 3090 Benchmarked Qwen QwQ AI Model – How Fast Is It?
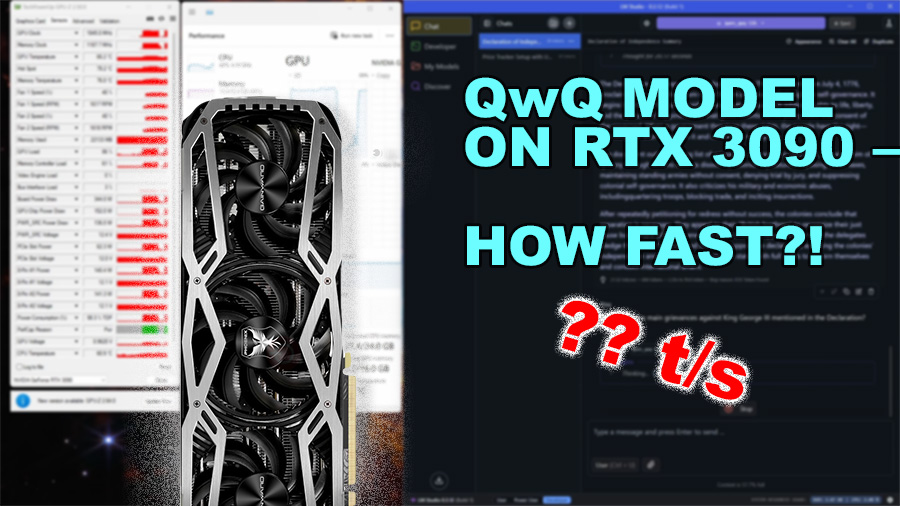
The recent release of Qwen’s QwQ 32B reasoning model has sparked interest among AI enthusiasts seeking ChatGPT o1 and o3-like capabilities in a locally-run solution. With its 32 billion parameters and advanced reasoning capabilities, QwQ represents a significant computational challenge for consumer GPUs. In this in-depth analysis, we’ll examine how the NVIDIA RTX 3090 handles this model in a practical, real-world environment rather than in idealized benchmarking conditions. For a broader comparison of how different GPUs perform with LLM models, check out our detailed benchmarking article. Our test setup includes a system already under load with OBS recording, numerous browser tabs, and approximately 2GB of VRAM dedicated to desktop tasks – precisely the kind of multi-tasking scenario many users will encounter.
Loading QwQ with RTX 3090
The initial loading phase of QwQ 32B provides critical insights into the model’s memory requirements. Using LM Studio with a GGUF 4-bit quantized version of the model (approximately 19GB in size), loading the model with a 4096 token context length consumed around 20GB (22GB for the entire system) of VRAM on the RTX 3090. The loading process itself took roughly one minute to complete.
Notably, the system simultaneously utilized approximately 20GB of system RAM when loading. This substantial memory footprint underscores the resource-intensive nature of running large language models locally, even with quantization techniques applied.
Memory Pre-allocation: Understanding KV Cache Mechanics
An important technical consideration when running models like QwQ 32B is the concept of memory pre-allocation. LM Studio (and similar frameworks) implement fixed Key-Value (KV) Cache allocation, reserving memory for the entire specified context window upfront, regardless of actual usage. For example, setting an 8K token context window reserves memory for all 8K tokens even if the actual prompt contains only 550 tokens.
This approach stems from transformer architecture requirements, where the model maintains attention information for each processed token. Pre-allocation prevents performance-degrading dynamic memory reallocation during inference and ensures consistent performance. However, it also means that context length settings have significant VRAM implications – the larger the context window, the more memory required before processing even begins.
The memory scaling is proportional not only to context length but also to model size. A 32B parameter model like QwQ requires substantially more KV cache memory per token than smaller 7B models, creating a multiplicative effect on memory requirements.
Short Context Test
Our initial test with a minimal prompt yielded encouraging results. The model demonstrated reasonable responsiveness with performance metrics as follows:
- Time to first token: 0.17 seconds
- Generation speed: 23 tokens per second
These metrics establish a baseline for QwQ 32B running on the RTX 3090 under favorable conditions with minimal context. The sub-quarter-second time to first token particularly highlights the model’s potential for interactive applications when context remains small.
The 1600 Token Context Test
Increasing complexity, we prompted the model to summarize the Declaration of Independence, a document comprising approximately 1,600 tokens. This test provided insights into how the RTX 3090 handles moderate context sizes with QwQ 32B:
| Metric | Value |
|---|---|
| Prompt Processing Time | 3 seconds |
| Reasoning/Thinking Time | 20 seconds |
| Generation Speed | 21 tokens per second |
| GPU TDP | 100% |
| GPU Clock Speed | 1800 MHz |
| GPU Power Draw | 350W |
| GPU Load | 88% |
| GPU Temperature | 70°C |
The RTX 3090 maintained near-maximum token generation speed despite the increased context, with only a minor reduction from 23 to 21 tokens per second. However, the reasoning phase demonstrated the computational intensity of QwQ’s thinking process, requiring a full 20 seconds of 100% GPU utilization.
This test also revealed potential optimization opportunities. The full 350W power draw suggests that undervolting or implementing a specialized inference power profile could potentially improve efficiency without significantly impacting performance.
The 5000+ Token Context Test
Our most demanding test pushed the RTX 3090 near its memory limits with an 8,192-token context window allocation, though the actual context used was approximately 5,000 tokens. This configuration:
| Metric | Value |
|---|---|
| Prompt Processing Time | 8.5 seconds |
| Reasoning/Thinking Time | 23 seconds |
| Generation Speed | 19 tokens per second |
| GPU TDP | 100% |
| GPU Clock Speed | 1800 MHz |
| GPU Power Draw | 350W |
| GPU Load | 89% |
| GPU Temperature | 71°C |
Despite operating at near-maximum memory capacity, the RTX 3090 maintained a respectable 19 tokens per second generation rate – only a 17% reduction from the short context baseline. The longer reasoning time reflects both the increased context size and the complexity of the analytical task assigned.
This test highlights that while the RTX 3090’s 24GB VRAM buffer is sufficient for running QwQ 32B with extended contexts, users are approaching the practical limits of the card’s memory capacity. The 23GB VRAM utilization leaves minimal headroom for additional tasks, especially in multi-application environments.
Conclusion: The RTX 3090’s Continued Relevance
Based on our comprehensive testing, the RTX 3090 remains a compelling option for AI enthusiasts looking to run advanced 32B parameter models like QwQ locally in March 2025. Despite being superseded by newer architectures, its performance characteristics make it particularly attractive in the current market context:
- Consistent ~20 tokens per second generation across varying context sizes
- Sufficient VRAM (24GB) to handle extended contexts up to 8K tokens
- Solid versatility for handling both text and multimodal models (Flux, WAN 2.1)
- Favorable price-performance ratio given current RTX 4090 pricing and RTX 5090 availability issues
For users willing to optimize their setup further, offloading desktop rendering to an integrated GPU or running inference through streamlined environments like Ollama on Linux could potentially enable even larger context windows up to 16K tokens.
While newer GPUs like the RTX 4090 and 5090 would undoubtedly offer faster inference speeds, the RTX 3090 maintains its position as a practical and cost-effective solution for running advanced local LLMs, particularly given the current market dynamics. Its ability to handle reasoning-focused models like QwQ with acceptable performance makes it a viable option for users seeking local alternatives to cloud-based AI services.

Allan Witt
Allan Witt is Co-founder and editor in chief of Hardware-corner.net. Computers and the web have fascinated me since I was a child. In 2011 started training as an IT specialist in a medium-sized company and started a blog at the same time. I really enjoy blogging about tech. After successfully completing my training, I worked as a system administrator in the same company for two years. As a part-time job I started tinkering with pre-build PCs and building custom gaming rigs at local hardware shop. The desire to build PCs full-time grew stronger, and now this is my full time job.Related
Desktops
Dell refurbished desktop computers
If you are looking to buy a certified refurbished Dell desktop computer, this article will help you …
Guides
Dell Outlet and Dell Refurbished Guide
For cheap refurbished desktops, laptops, and workstations made by Dell, you have the option to use …
Guides
Refurbished, Renewed, Off Lease
When you are looking for refurbished computer, you often see – certified, renewed, and off-lease placed in …
Laptops
Excelent Refurbished ZenBook Laptops
If you are looking for a compact ultrabook and a reasonable price, consider a refurbished Asus Zenbook …
0 Comments