Best Laptop for LLMs like Llama and DeepSeek (2025 Update)
We’ve updated our top pick: the MacBook Pro with M3 Max (96GB) is now our recommended laptop for running large language models (LLMs) like Llama 3.2, Mistral, DeepSeek, and Qwen. This model surpasses our previous choice, offering better memory capacity and improved performance for on-the-go inference.
The 96GB unified memory allows for smooth execution of 70B models with large context windows and even 70B q8_0 (75GB), which was previously impractical on most laptops. With 400GB/s bandwidth, it performs 1.5x faster than the newly released competitors like NVIDIA DGX Spark and AMD Strix Halo in mobile AI workloads.
Compared to Windows laptops, which are now limited to 24GB VRAM, the M3 Max offers a superior experience for local LLM inference on a large model. While desktop GPUs like the RTX 4090 (24GB) still have higher raw power, the MacBook’s unified memory and bandwidth make it the best portable option available today.

Apple Silicone M3 Max chip on a MacBook Pro motherboard includes everything in a single package – CPU, GPU, unified memory, and the controllers.
Non-Apple alternatives have improved with the release of 24GB VRAM versions featuring the RTX 5090, but they still cannot fully load 70B models into VRAM and must rely on slower system memory. However, with 24GB VRAM, they can now run 32B models such as Qwen’s QwQ reasoning model with ease. Additionally, the RTX 5090 boasts 896GB/s bandwidth, more than twice that of the M3 Max (400GB/s), making it significantly faster when models fit entirely within VRAM.
Compared to Windows laptops, which previously struggled with models larger than 13B, these new GPUs help improve performance for 33B models. However, their reliance on DDR5-4800 system memory (72GB/s) when exceeding VRAM limits still results in a sharp performance drop. In contrast, the M3 Max’s unified memory maintains higher bandwidth and smoother operation, making it the superior choice for LLM inference on the go. For those who need portability without sacrificing model size, the MacBook Pro M3 Max (96GB) remains the best option.
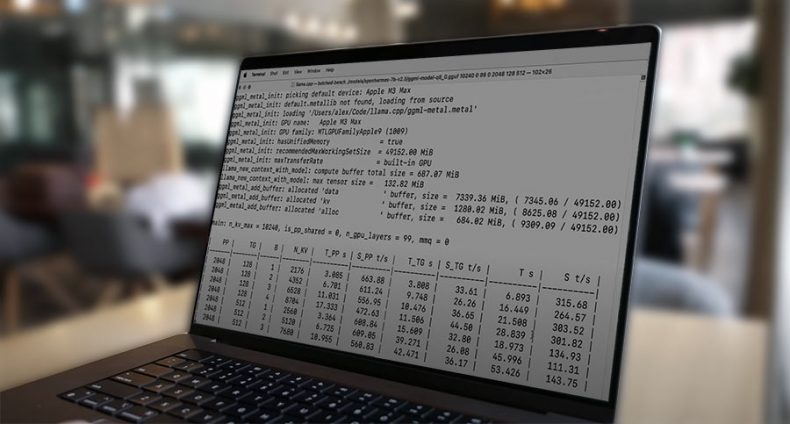
M3 Max Laptop LLM inference speed:
| Model name | Model Size | Speed (t/s) |
|---|---|---|
| Mistral-Nemo-Instruct-2407 | 7B_q4_0 | 66.31 |
| Mistral-Nemo-Instruct-2407 | 7B_q5_0 | 60.1 |
| Mistral-v0.3-7B-ORPO | 7B_q8_0 | 42.75 |
| LLaMA2-13B-Tiefighter | 13B_q4_0 | 36.49 |
| LLaMA2-13B-Tiefighter | 13B_q5_0 | 34.2 |
| Mistral-Nemo-Instruct-2407-f16 | 7B_f16 | 25.09 |
| LLaMA2-13B-Tiefighter | 13B_q8_0 | 21.18 |
| WizardLM-30B | 30B_q4_0 | 16.24 |
| WizardLM-30B | 30B_q5_0 | 14.44 |
| dolphin-2.7-mixtral-8x7b | 8x7B_q5_0 | 25.12 |
| WizardLM-30B | 30B_q8_0 | 9.1 |
| Airoboros-65B-GPT4-2.0 | 65B_q4_0 | 3.14 |
| Meta-Llama-3.1-70B-Instruct | 70B_q4_0 | 3.11 |
If you’re open to sacrificing a bit of performance – roughly 7-8% in inference speed and about 20% in prompt processing speed – then the MacBook Pro with M2 Max is still as viable alternative. It offers the same unified memory bandwidth as the M3, but with a slightly lower GPU core count (38 against 40). This difference, while noticeable, isn’t drastic. For instance, when running a 7B 4-bit quantized model, the difference in inference speed is only about 10 tokens per second. So, for those who are budget-conscious or don’t need the absolute peak of performance, the M2 Max stands as a solid choice, balancing cost with capability.
Windows and Linux based Laptops for LLM
If you’re looking to step outside the Apple ecosystem and are in the market for a Windows or Linux-based laptop, there are several options you might consider: the RTX 3080 with 16GB, RTX 3080 Ti with 16GB, RTX 4090 with 16GB, or a model equipped with the RTX 5090 with 24GB.
The maximum VRAM you’ll typically find in a PC-based laptop is 24GB. This capacity is adequate for models up to 32B. However, for anything beyond that, you’ll need to split the load between VRAM and RAM to manage the higher memory demands. This split, unfortunately, leads to a significant reduction in inference speed.
Among these options, mobile GPUs like the RTX 4080, boasting a bandwidth of 432.0 GB/s, can offer speeds comparable to the M3 Max in terms of tokens per second. However, the RTX 4080 is somewhat limited with its 12GB of VRAM, making it most suitable for running a 13B 6-bit quantized model, but without much space for larger contexts. To get closer to the MacBook Pro’s capabilities, you might want to consider laptops with an RTX 4090 or RTX 5090.
In particular, the mobile RTX 5090, with its 896 GB/s bandwidth, offers better inference speeds than the RTX 4090. It also comes with 24GB of VRAM, allowing it to handle up to 32B models with more context space.
This positions RTX 5090-equipped laptops as a closer, albeit not perfect, alternative to the MacBook Pro in terms of LLM performance, keeping in mind the limitations when compared to Apple’s unified memory system.
Here are the best PC-based laptops for LLM inference:

Lenovo has made some intriguing changes this year, especially with the GPU upgrade. Let’s break down the key hardware aspects and how they fit into the realm of LLM (Large Language Model) inference:
GPU – Nvidia RTX 5090 (24GB GDDR7): This is a major upgrade over previous mobile GPUs, offering 896GB/s bandwidth, making it one of the fastest options in a laptop today. While it cannot fully load 70B models into VRAM, it can handle 32B models entirely in VRAM, such as Qwen’s QwQ reasoning model, without relying on system memory. For larger models, it will require system memory offloading, which is slower but improved over DDR5-4800 setups.
CPU – Intel Core Ultra 9 24-Core: A high-end choice for LLM tasks, handling data loading, preprocessing, and prompt management efficiently. The AI-accelerated features of Intel’s Ultra series may offer additional optimizations for inference workloads.
RAM – 64GB DDR5-6400: The higher 6400MT/s speed (102GB/s bandwidth) is a significant improvement over DDR5-4800 (76.8GB/s), reducing the performance hit when offloading LLM parameters to system memory. However, VRAM is still the primary constraint, so models larger than 32B will experience some slowdown.
Overall, the Lenovo Legion Pro 7i offers high performance-per-dollar and is one of the best non-Apple laptops for local LLM inference. While it still can’t match Apple’s unified memory advantage for massive models, its RTX 5090 and high-speed RAM make it a powerful option for enthusiasts looking to push beyond 13B models without stepping up to a desktop setup.
MSI Raider GE68HX 13VI

MSI Raider GE68, with its powerful CPU and GPU, ample RAM, and high memory bandwidth, is well-equipped for LLM inference tasks.
CPU – Intel Core i9-13950HX: This is a high-end processor, excellent for tasks like data loading, preprocessing, and handling prompts in LLM applications. The increased performance over previous generations should be beneficial for running LLMs efficiently.
GPU – Nvidia RTX 4090 Mobile (576.0 GB/s bandwidth): This GPU is a greate, especially for LLM tasks up to 13B model. The high memory bandwidth is crucial for handling large models efficiently. Although it’s a mobile version and might not reach the peak performance of its desktop counterpart, it’s still significantly powerful for running LLM models.
RAM – 64 GB of DDR5 5200 memory (83.2 GB/s memory bandwidth): The ample RAM and high memory bandwidth are ideal for LLM tasks. This amount of RAM surpasses the minimum requirements for most LLM models, ensuring smooth operation even with larger context.

Allan Witt
Allan Witt is Co-founder and editor in chief of Hardware-corner.net. Computers and the web have fascinated me since I was a child. In 2011 started training as an IT specialist in a medium-sized company and started a blog at the same time. I really enjoy blogging about tech. After successfully completing my training, I worked as a system administrator in the same company for two years. As a part-time job I started tinkering with pre-build PCs and building custom gaming rigs at local hardware shop. The desire to build PCs full-time grew stronger, and now this is my full time job.5 Comments
Leave a Reply to Panos Cancel reply
Related
Desktops
Best GPUs for 600W and 650W PSU
A high-quality 500W PSU is typically sufficient to power GPUs like the Nvidia GeForce RTX 370 Ti or RTX 4070.
Guides
Dell Outlet and Dell Refurbished Guide
For cheap refurbished desktops, laptops, and workstations made by Dell, you have the option…
Guides
Dell OptiPlex 3020 vs 7020 vs 9020
Differences between the Dell OptiPlex 3020, 7020 and 9020 desktops.
I am considering M1 Max as a more budget option can you comment a bit about the difference between the two when running large language modes.
You can check out our article on the best Mac for LLMs. Generally, for token generation, the M2 Max with a 38-core GPU is about 8% faster than the M1 Max with a 32-core GPU. This translates to around 7 or 8 additional tokens when performing inference on a 7B model with 4-bit quantization.
For prompt processing, the difference is more substantial – about 26% – as prompt processing is compute-bound, and the M2 Max has an advantage in that area. In contrast, token generation is bandwidth-bound, and both models have the same bandwidth at 400GB/s.
I have the M1 Max, and it’s a beast. A colleague of mine has the M2 Max MacBook Pro, and honestly, the difference is barely noticeable. Sure, the M1 is a bit slower with prompt processing, but that only really matters if you’re working with huge contexts like 16k or 32k tokens.
In general, if you’re planning to do long chats with large models, processing will slow down as the context size grows. For example, on the M1 Max, processing a 12k context can take over 6 minutes.
In an effort to approach the response quality of Claude Sonnet, I am considering Mixtral 12.9B with 8-bit quantization either on a Macbook Pro M4 Max with 128GB memory or on a Mac Studio M2 Ultra with 192GB memory. Are there pros and cons for either option?
I would like to be able to include my document dataset of a few GB and also be able to use websites (URLs) as content sources.
Any comments? Thanks in advance.
For a Claude Sonnet-like experience, you’ll want DeepSeek-V2.5, a powerful Mixture of Experts (MoE) model with 238 billion parameters, featuring 160 experts and 16 billion active parameters. To run this model, you’ll need a Mac Studio M2 Ultra with 192GB of memory since the Q4 GGUF quantized version of the model takes up 142.45GB.
If you’re going to use MacBook Pro M4 Max with 128GB of memory, your best options are Mistral Large 2411, Mistral Small 24B 2501 and Qwen2.5 72B.